- Researchers from ─ó╣Į╩ėŲĄ, Caltech, the University of Chicago, and Harvard created a rare topologically ordered state of matter on ─ó╣Į╩ėŲĄ's System Model H2 and used it to perform protected universal quantum gates with non-Abelian anyons.
- The work explores an alternative approach to fault tolerance by using topological properties to protect quantum information. This could reduce the need for magic state distillation, which can (in some circumstances) be resource-intensive.
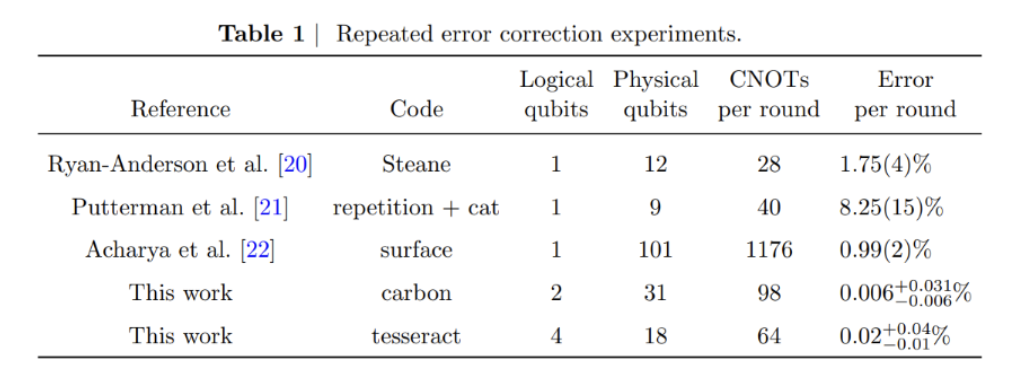
- ─ó╣Į╩ėŲĄ continues to show leadership in fault tolerance, with successful demonstrations spanning world record error rates to exotic approaches like topological computing
Quantum computing is all about putting the exotic properties of physics to work. Qubits can exist in two states at once, like the famous cat that is both alive and dead. Qubits can also be entangled, where the state of one will instantaneously affect the state of another - even when they have no way to ŌĆ£talkŌĆØ to each other. Qubits can even be teleported, moving a quantum state from one place to another without physically moving it through space.
These features give quantum computing its power. But the ŌĆśspookyŌĆÖ nature of quantum computing doesnŌĆÖt stop there: our quantum computers are potent enough to make exotic states of matter out of our qubits, and to perform calculations that would warp the mind of more traditional thinkers.
A new approach
In a recent paper published in Nature, researchers at ─ó╣Į╩ėŲĄ teamed up with Caltech, the University of Chicago, and Harvard to create a rare ŌĆśtopologically orderedŌĆÖ state of matter from our qubits.
When the qubits become ŌĆśtopologically orderedŌĆÖ, they become more than individual particles, now ŌĆśrelatedŌĆÖ to each other in a specific way. This is like how hydrogen and oxygen act as individual gas particles alone, but you can put them together in a certain way so that they become water, a liquid, and an entirely different creature.
When the qubits become topologically ordered, the quantum information that they carried individually gets spread out over the whole system, which acts as a sort of protection from noise. This is like how a net makes a stronger barrier than a bunch of un-knotted ropes.
Once the researchers had topologically ordered qubits, they used the exotic particles that resulted (called non-Abelian anyons) to compute, performing error-protected gates and measurements.
To perform gates, the researchers 'braided' the anyons, which is like changing the shape of the ŌĆ£netŌĆØ. This is something like the childrenŌĆÖs game ŌĆścats cradleŌĆÖ. Through a sequence of changes to the ŌĆ£netŌĆØ, the quantum computer can perform full calculations, one day helping scientists to understand the secrets hidden in the world around us.
Why go to such trouble? Well, for the love of discovery of course - but the team had an additional, specific motivation. One of the biggest challenges in building practical quantum computers is protecting them from errors while still being able to perform every operation needed for computation (this is referred to as universality).
This work takes a fresh approach to this challenge. Unlike traditional quantum error correction, the special properties of topological matter enable a universal set of fault tolerant gates without relying on expensive magic state distillation.
Why this matters
Quantum error correction is essential for large-scale quantum computing. While it protects fragile quantum information from noise by turning delicate physical qubits into robust logical qubits, it also introduces a significant constraint: not every quantum gate can be performed directly on logical qubits.
For decades, the standard solution has been to supplement error-corrected operations with magic states. These specially prepared quantum resources enable universal computation but can come at a steep cost - in many estimates of future fault-tolerant quantum computers, magic state preparation dominates both the physical qubit count and the runtime of useful algorithms.
Reducing this overhead has therefore become an important goal in quantum computing. This new approach may significantly reduce the cost by enabling the ŌĆśtopological preparationŌĆÖ of magic states, eliding expensive protocols like distillation. If universal computation can be performed without large-scale magic state distillation, quantum computers could require significantly fewer physical qubits and spend much less time generating computational resources before running useful algorithms.
We will never stop exploring
While there is still considerable work ahead to understand the practical implementation and scalability of these ideas, this result expands the landscape of what's possible in quantum fault tolerance.
Of course, this impressive demonstration describes just one approach we are taking to fault tolerance at scale. We will continue to push forward with topological computing alongside more traditional approaches to quantum error correction, as well as exploring everything we can imagine in between. We are looking at a number of ways to reduce the resource cost of magic states in particular, and are making strides in multiple dimensions. With machines that are both flexible and accurate enough to do it all, who can resist?